What is K-Nearest Neighbors?
The K-Nearest Neighbors algorithm works on a simple assumption: similar objects tend to be found near each other. It’s like when you’re in a huge library looking for books on, let’s say, baking. If you don’t have a guide, you’ll probably just grab books randomly until you find a cooking book, and then start grabbing books nearby as you hope they’re about baking because cookbooks are usually kept in the same spot.
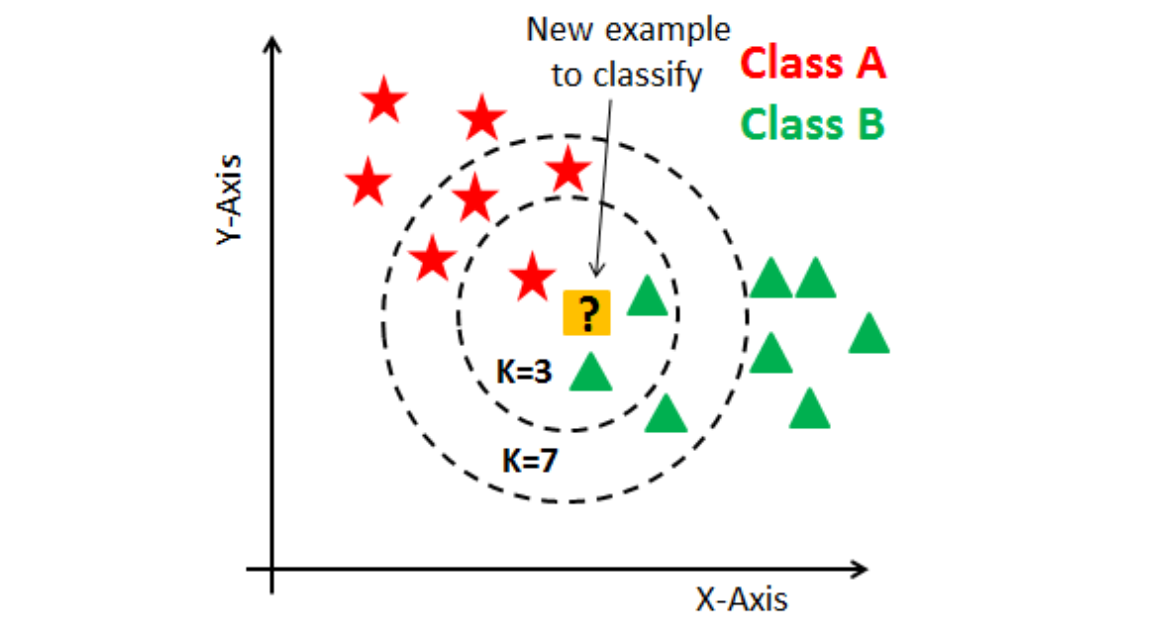
How does KNN work?
KNN is like the memory whiz of machine learning algorithms. Instead of learning patterns and making predictions like many others do, KNN remembers every single detail of the training data. So, when you throw a new piece of data at it, it digs through everything it remembers to find the data points that are most similar to this new one. These similar points are its ‘nearest neighbors.’ To figure out which neighbors are closest, the algorithm measures the distance between the new data and everything it knows using methods like Euclidean or Manhattan distance. The choice of method matters a lot because it can change how KNN performs. For example, Euclidean distance works great for continuous data, while Manhattan distance is a go-to for categorical data.
After measuring the distances, KNN picks the ‘k’ closest ones. The ‘k’ here is important because it’s a setting you choose, and it can make or break the algorithm’s accuracy. If ‘k’ is too small, the algorithm can get too fixated on the noise in your data, which isn’t great. But if ‘k’ is too big, it might consider data points that are too far away, which isn’t helpful either. For classification tasks, K-Nearest Neighbors looks at the most common class among these ‘k’ neighbors and goes with that. It’s like deciding where to eat based on where most of your friends want to go. For regression tasks, where you’re predicting a number, it calculates the average or sometimes the median of the neighbors’ values and uses that as the prediction. What’s unique about KNN is it’s a ‘lazy’ algorithm, meaning it doesn’t try to learn a general pattern from the training data. It just stores the data and uses it directly to make predictions. It’s all about finding the nearest neighbors based on how you define ‘closeness,’ which depends on the distance method you use and the value of ‘k’ you set.
What’s unique about KNN is it’s a ‘lazy’ algorithm, meaning it doesn’t try to learn a general pattern from the training data. It just stores the data and uses it directly to make predictions.
Contrary to popular belief, Lorem Ipsum is not simply random text. It has roots in a piece of classical Latin literature from 45 BC, making it over 2000 years old. Richard McClintock, a Latin professor at Hampden-Sydney College in Virginia, looked up one of the more obscure Latin words, consectetur, from a Lorem Ipsum passage, and going through the cites of the word in classical literature, discovered the undoubtable source. Lorem Ipsum comes from sections 1.10.32 and 1.10.33 of "de Finibus Bonorum et Malorum" (The Extremes of Good and Evil) by Cicero, written in 45 BC. This book is a treatise on the theory of ethics, very popular during the Renaissance. The first line of Lorem Ipsum, "Lorem ipsum dolor sit amet..", comes from a line in section 1.10.32.